概要
読取元のテーブルからデータを取得、データの加工し、書込み先のテーブルへ書き込む場合に実装方法にどの様に実行時間が変化するのかを「単発のinsertをレコード数繰り返す」、「bulk insert」、「insert-select」のケースで検証します。
環境
Databaseサーバ
- Oracle VM VirtualBox version.4.0.8
- Oracle Linux Server release 5.5
- Oracle Database 11g Enterprise Edition Release 11.2.0.1.0
プログラム実行環境(APサーバの代わり)
- Windows 7 Ultimate
- Eclipse Java EE IDE for Web Developers.Helios Service Release 1
- S2JDBC
- Java 6.0 update 18
結果
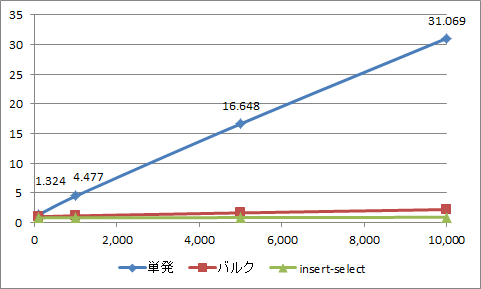
今回、特にデータの加工は行わず、同一構造の2つのテーブルを使用し読取元テーブルから書込み先テーブルへデータをコピーしました。カラム数は2項目のみです。
データ数は100、1,000、5,000、10,000、50,000で行いました。下のグラフでは10,000件までを表示していますが、50,000件でもほぼ同じ比率で時間が掛っていました。
基本的な処理の流れはデータの読み取り、データ加工、データ書き込みですが、データ加工をどこで(DB/APサーバ)行うかによってネットワークにデータが流れたり加工処理の負荷を担う場所が変わったりしますし、insertの発行回数でDBサーバでのSQLのパースが行われる回数が変わります。
また要件次第ですが、insert-selectでは複雑な加工を行うのが難しいので、複雑な要件を含む場合はAPサーバ側で行うのが良いと思います。
なお、Java側でのinsert文(Bulk含む)の発行はS2JDBCで行っています。
3種類の比較(縦軸:実行時間(秒)、横軸:データ件数)
bulk insertとinsert-selectの抜粋(縦軸:実行時間(秒)、横軸:データ件数)
